
From Open to Reusable: How FAIR² Data Portals Multiply Scientific Impact
Designing data for discovery, trust, and real-world reuse—by scientists, for scientists


The Problem: When ‘Open’ Isn’t Reusable
If you’ve ever tried to reuse a public dataset, you’ve likely hit the same walls as the rest of us: a jumble of files with unclear structure, cryptic variable names, scant methods, or links that lead nowhere. Despite the best intentions of “open science,” vital context—what was measured, how, by whom, and why—too often gets lost along the way. The result? Valuable data sits idle, or worse, gets misunderstood and misused.
As our research becomes more interdisciplinary and as AI enters every aspect of data analysis, these challenges are magnified. Data needs to be more than just available; it needs to be discoverable, understandable, interoperable, and ready for both human and machine use. Without this, reproducibility suffers, opportunities for collaboration are lost, and datasets don’t get the recognition—or citations—they deserve.
This is the motivation behind the FAIR² data portal approach: designing every detail with the goal of making data not just open, but truly reusable, impactful, and trusted by a broad community of users.
The FAIR² Vision: Data Designed for Reuse, Trust, and Impact
The FAIR principles—Findable, Accessible, Interoperable, and Reusable—were created to address many of the pain points in data sharing and reuse. But as the scale and complexity of scientific data have grown, so too have our expectations. Today’s research landscape doesn’t just need data that can be found and downloaded. It needs data that is ready to fuel machine learning, adaptable to new questions, responsibly managed, and useful far beyond its original context.
That’s where FAIR² comes in.
FAIR² builds upon the foundational FAIR principles, but goes further by explicitly including AI-Readiness and Responsible AI alignment. This means designing datasets not just to be accessed, but to be immediately usable by both humans and machines—supporting everything from classic ecological analysis to state-of-the-art AI modeling, and always with ethical and societal considerations in mind.
Introducing the FAIR² Data Portal
Every feature in a FAIR² portal is carefully engineered to solve a real-world problem that scientists, data stewards, and policy makers encounter. The goal: to make sure every dataset is not only available, but actionable, trustworthy, and impactful—maximizing its value for research, education, and decision making.
All portal images are from the inaugural FAIR² Data Portal (Borja et al, 2025).
Core Features & Scientific Rationale
Every detail of the FAIR² portal is designed to remove friction for scientists and ensure that data is not just available, but meaningfully usable, citable, and impactful. Here’s how each core feature supports this vision:
⸻
Interactive Data Explorer
The problem it solves:
Before investing time in downloading and processing a dataset, researchers want to know: What variables are available? Over what time period and geography? Are there gaps, outliers, or patterns I should know about?
How it helps:
The Data Explorer provides instant, visual access to dataset content. Researchers can filter, subset, and visualize data directly in the portal, speeding up hypothesis generation and enabling smarter, faster decisions about which data to use and cite.
⸻
Croissant Data Package & FAIR² Extensions
The problem it solves:
Machine learning and advanced analytics require data that’s well-structured, documented, and compatible across platforms. But standard research data rarely meets the technical expectations of modern AI workflows.
How it helps:
The FAIR² portal delivers datasets in the Croissant format from MLCommons—a format already recognized in the ML community (TensorFlow, JAX, Kaggle, Hugging Face, and more). FAIR² then extends Croissant to include full scientific metadata, detailed methods, provenance, contributor lists, and ready-to-use citation files.
This ensures that data can move seamlessly from traditional scientific analysis into the heart of machine learning projects, while remaining transparent and trustworthy for academic reuse.
⸻
Jupyter & Google Colab Integration
The problem it solves:
Complex data analyses often stall at the setup phase—installing dependencies, importing data, or figuring out column names.
How it helps:
Every dataset comes with ready-to-launch Jupyter notebooks and Google Colab support, complete with example code, embedded documentation, and variable explanations. This lowers the barrier for new users, speeds up onboarding, and increases the chance your data is reused, cited, and built upon.
⸻
Open FAIR² Metadata API
The problem it solves:
Researchers and developers need to programmatically discover, query, and retrieve data. Yet most datasets have scattered or inaccessible metadata.
How it helps:
FAIR² exposes all metadata in an open, machine-readable format (fair2.json). This API includes structured metadata and direct links to underlying datasets. Anyone can access this metadata—whether using a Python toolkit, standard web call, or another application—making automated analysis, discovery, and integration simple and robust.
⸻
Full Methods & Contextualized Data Dictionary
The problem it solves:
Even “open” data is often useless without context: How was each variable measured? What does “Station 21” or “NO3” mean? What were the calibration protocols or QA steps?
How it helps:
FAIR² portals provide full, detailed methods sections directly linked to a contextualized data dictionary. Each variable is explained in plain language, with direct links to collection protocols and relevant QA/QC documentation. This makes the data genuinely reproducible, supporting credible citations and secondary analyses.
⸻
CLARA: The AI Data Steward
The problem it solves:
Scientists, students, and policy makers alike have questions—about methods, provenance, or basic terminology. Waiting for a response from a busy PI is inefficient, and reading dense documentation can be daunting.
How it helps:
CLARA, the AI data steward, is always available to answer questions in real time. Whether you want a technical explanation (“How were samples validated in 2005?”) or a layperson’s summary (“What does this dataset measure?”), CLARA can help—making the portal accessible to everyone, not just domain experts.
⸻
AI-Generated Outreach Tools
The problem it solves:
Many valuable datasets never reach their full audience—whether in science, policy, or the public—because researchers lack time or resources for outreach.
How it helps:
The FAIR² portal includes automatically generated podcasts and social posts summarizing the dataset, its context, and findings. This increases discoverability, drives new citations, and ensures that datasets are recognized and reused far beyond their initial publication.
⸻
Contributor Recognition
The problem it solves:
Scientific data is built by teams, not individuals—but contributors beyond first authors are often invisible.
How it helps:
Each FAIR² dataset credits all contributors (with roles, affiliations, and ORCIDs), ensuring everyone gets the credit they deserve and making proper citation straightforward.
⸻
Usage Metrics & Community Feedback
The problem it solves:
Without transparent feedback and metrics, it’s difficult to track data impact or improve quality over time.
How it helps:
Usage statistics, citation tracking, and open review tools help data creators and users see how data is being used, cited, and improved—supporting funding, collaboration, and career progression.
⸻
FAIR² Compliance Certification
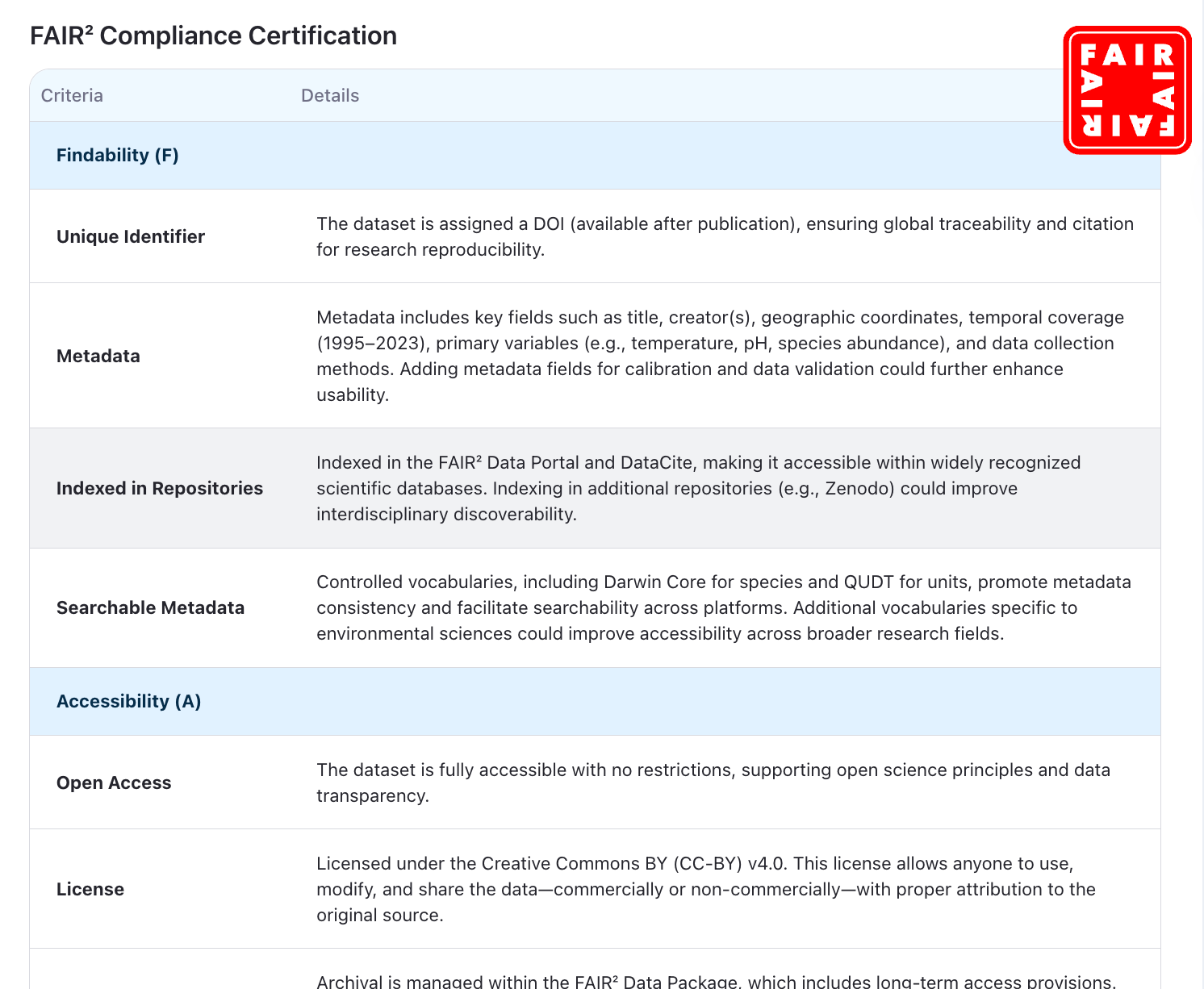
The problem it solves:
Funders, journals, and users want more than claims of “openness”—they want evidence of best practice.
How it helps:
Every dataset is assessed and certified against FAIR² criteria: Findability, Accessibility, Interoperability, Reusability, AI-Readiness, and Responsible AI. Certification is transparent, with actionable recommendations for further improvement, building trust for everyone who relies on the data.
⸻
Data Visitation & Controlled Access
The problem it solves:
Not all data can be fully open. Sometimes legal, ethical, or privacy constraints apply.
How it helps:
FAIR² supports data visitation—open metadata remains FAIR for all, while actual data access can be controlled and provided with appropriate credentials. This ensures sensitive data can still be discovered and reused by qualified users, without ever closing off the metadata or record of existence.
Currently, FAIR² is focused on fully open data, but the architecture is designed for future controlled access as needed.
Interoperability: Croissant for Machine Learning, FAIR² for Science
For data to reach its full impact, it must be able to move seamlessly between research disciplines and technical ecosystems. Today, that means datasets should be as usable by a machine learning engineer on Kaggle as by a scientist conducting a meta-analysis for a journal review.
FAIR² data portals achieve this through full compatibility with the Croissant format developed by MLCommons. Croissant is quickly becoming the standard for structuring datasets in machine learning. When a dataset is Croissant-compatible, it can be imported directly into frameworks like TensorFlow, JAX, Hugging Face, or into competition platforms like Kaggle—without the need for custom scripts or conversion headaches.
But scientific research requires more than technical access: context, trust, and proper citation are essential. This is where FAIR²’s extensions come into play. Every FAIR² dataset provides:
• Comprehensive scientific metadata: Each dataset includes detailed context about what was measured, by whom, where, when, and using what protocols.
• Linked methods and provenance: Researchers can trace every variable back to its data collection and processing method, supporting reproducibility and scholarly review.
• Contributor and citation records: Full author lists, roles, and affiliations are maintained, ensuring transparency and easy attribution.
• Standardized scientific data units: Variables are clearly annotated with standardized units (such as those from QUDT or other scientific vocabularies), ensuring that data can be merged, compared, or interpreted correctly by both humans and machines.
• Versioning and citation files: Every dataset comes with persistent identifiers and clear versioning, so you—and anyone reusing your data—can always refer to exactly the right release.
What’s the result?
A dataset published through a FAIR² portal is instantly ready for analysis by machine learning tools and for in-depth scientific inquiry. An ecologist can analyze trends using the Data Explorer or a Jupyter notebook, while a machine learning engineer can spin up a model on the same dataset in Hugging Face. Both can trust the data’s scientific meaning, methods, and provenance—while reviewers, funders, and future users see exactly who created the data and how to cite it.
By bridging these worlds, FAIR² doesn’t just make data open. It makes data truly interoperable—supporting reusability, trust, and impact across the full research and AI spectrum.
The Data Article: The Citation of Record
One of the central goals of FAIR² is not just to make data usable, but also to make it citable in a way that fits seamlessly into standard scholarly workflows. Every FAIR² portal dataset is linked to a peer-reviewed FAIR² Data Article, published with its own DOI. This Data Article serves as the definitive, persistent citation for the dataset.
Why does this matter?
Citing the Data Article is the gold standard for scholarly attribution:
• Standard practice: Journals, repositories, and citation indexes recognize Data Articles and their DOIs just like traditional research papers. This means your dataset gets counted and tracked in the places that matter most for career advancement, grant applications, and institutional reporting.
• Complete context: The Data Article goes beyond metadata—it describes the dataset’s rationale, collection protocols, structure, provenance, and intended use, all in a peer-reviewed format. Readers get both the story and the science, supporting both transparency and trust.
• Seamless access: The Data Article links directly to the FAIR² Data Portal, so anyone citing your work can instantly explore, reuse, or verify the underlying data.
For researchers who reuse a FAIR² dataset, citing the Data Article is clear, unambiguous, and fully aligned with existing scientific best practice. It ensures that all contributors are credited, the dataset is easily discoverable, and impact is visible—not just in download counts, but in the scholarly record.
Real-World Impact: Who Benefits and How
The true value of the FAIR² approach isn’t just in its technical rigor—it’s in how it changes the daily experience of researchers, students, data scientists, and decision-makers who depend on high-quality data. Here’s how different communities benefit from the FAIR² portal in practice:
⸻
For Scientists:
You gain instant, clear access to methods, protocols, and well-documented variables, whether you’re an expert in the field or a newcomer. Suppose you’re preparing a meta-analysis of marine ecosystems: with FAIR², you can rapidly scan data coverage in the Explorer, review full methods linked to each variable, and trust that every measurement is grounded in transparent, standardized protocols. The data package is ready for direct import into your analysis pipeline, and when you publish, you can cite the Data Article with confidence that it will be recognized by reviewers and tracked by funders.
⸻
For Machine Learning Engineers and Data Scientists:
Datasets are already in Croissant format—meaning you can load them straight into TensorFlow, JAX, or Hugging Face, with no conversion needed. Metadata, units, and labels are machine-readable, so model building starts immediately. The open fair2.json metadata and API links make automation, benchmarking, and large-scale integration painless.
Result: faster project starts, fewer errors, and the assurance that models are trained on well-documented, scientifically validated data.
⸻
For Policy Makers and Non-Experts:
CLARA, the AI data steward, offers plain-language answers to questions about what’s in the dataset, how measurements were made, and what the results mean. Whether you need to understand water quality for a legislative briefing, check biodiversity indicators for a regional report, or explain a variable to a general audience, CLARA delivers clarity—supported by open, peer-reviewed methods and context.
⸻
For Students and Early-Career Researchers:
Getting started with new data can be intimidating. FAIR² portals remove the guesswork, providing clear onboarding with Jupyter/Colab notebooks, full data dictionaries, and accessible documentation. Students can learn, experiment, and contribute without the frustration of missing context or cryptic code.
⸻
For the Broader Community:
Every dataset is discoverable and reusable far beyond its original discipline. AI-generated podcasts and social media summaries amplify outreach, while open metrics and feedback loops keep the data ecosystem evolving in response to real user needs.
⸻
In all these cases, the core value is the same: data that travels, inspires, and endures—serving science, policy, and education, while ensuring every contributor is credited and every reuse is supported by trust and transparency.
Conclusion: Help Shape Data That Travels, Inspires, and Endures
The FAIR² data portal is more than just a technology platform—it’s a vision for how research data can truly serve science and society: accessible, understandable, actionable, and impactful. By reimagining every stage of the data lifecycle—from rich metadata and standardized formats to transparent documentation, open APIs, and AI-powered assistance—FAIR² ensures data is not only stored, but genuinely shared and used.
But this vision depends on all of us. The FAIR² specification and trademark will be owned and maintained by a non-profit foundation, governed by the scientific community itself. Our goal is to work together—across disciplines and sectors—to ensure that the FAIR² data model reflects the needs, practices, and values of science as a whole. Community governance means your voice, experience, and critique genuinely shape the rules, standards, and evolution of FAIR².
We want to hear from you:
What features would make FAIR² even more valuable in your daily work?
Where can we improve clarity, trust, or usability for your field?
How can we make the platform more responsive to scientists, data stewards, policymakers, and the public?
What would you want to see in a transdisciplinary, common data model for science?
Share your feedback, critiques, and bold ideas. Join the conversation—in the comments, via direct message, or through the portal’s community channels.
Explore a FAIR² portal, try out the features, cite the FAIR² Data Article, and ask CLARA your toughest data question. Most importantly, help us build a movement—so that scientific data not only exists, but thrives, inspires, and accelerates discovery for everyone.
Let’s create the future of open, reusable science—together.
Links:
Frontiers FAIR² Data Management Pilot
FAIR² Website: www.fair2.ai